
Designing Memory Strategy for Agentic Systems
A customer drives into the service lane with a 2022 Camry and a complaint that sounds simple. The brakes are making noise again. The AI service advisor takes it from there. It checks open recalls against NHTSA and the manufacturer. It pulls the vehicle and its service history. It reasons about the likely cause and drafts a recommendation. Then it pauses, because this step needs a human advisor to approve the work before anything is scheduled.
That pause is where most agentic systems quietly fall apart.
The advisor steps away to help another customer. The session times out. A process restarts. A browser tab closes. When the workflow comes back, the agent has no idea where it was. The recall check is gone. The diagnosis is gone. The approval that was halfway done is gone. The customer gets asked the same questions they already answered ten minutes ago, and the trust you were trying to build evaporates.
The agent did not fail at reasoning.
It failed at memory.
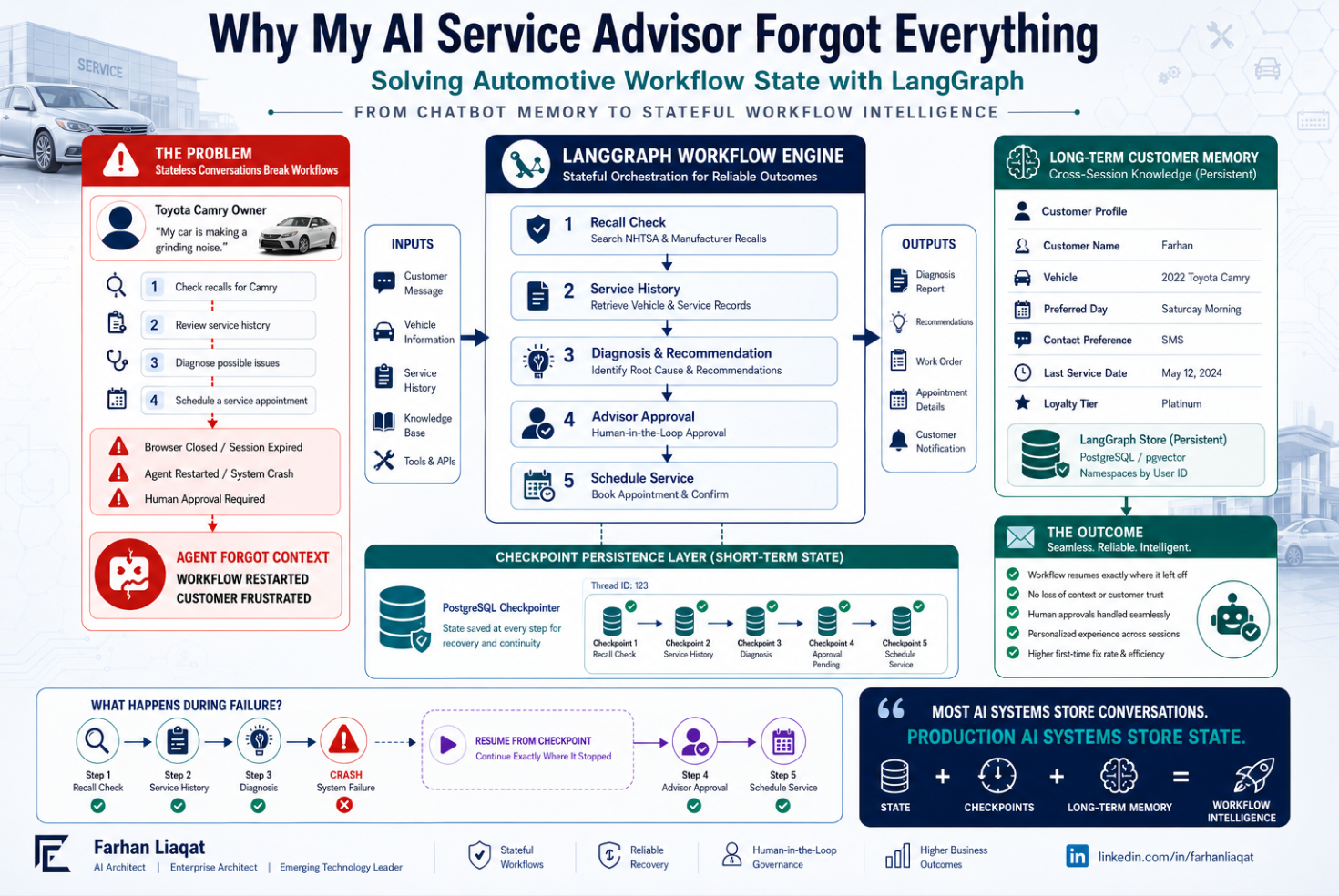
A reliable service advisor needs workflow state, checkpoint recovery, and long-term customer memory working together.
The mistake is treating memory as storage
The most common version of this problem starts with good intentions. The team decides the agent should remember things, so they store everything. Every conversation message. Every tool call. Every retrieval result. Every intermediate reasoning step. Keep all of it, just in case.
That feels safe.
It is not.
Store everything and you end up with higher cost, a larger attack surface, real privacy exposure, bloated context windows, and a memory that gets less useful as it grows. The signal drowns in the noise. More stored does not mean more remembered. A system that keeps everything is not a system with a good memory. It is a system with no memory strategy at all.
The better question is not what you should store.
It is what the system should actually remember.
Three layers, told through one repair
Building a LangGraph service advisor, the cleanest way I found to answer that question was to stop treating memory as one thing and start treating it as three.
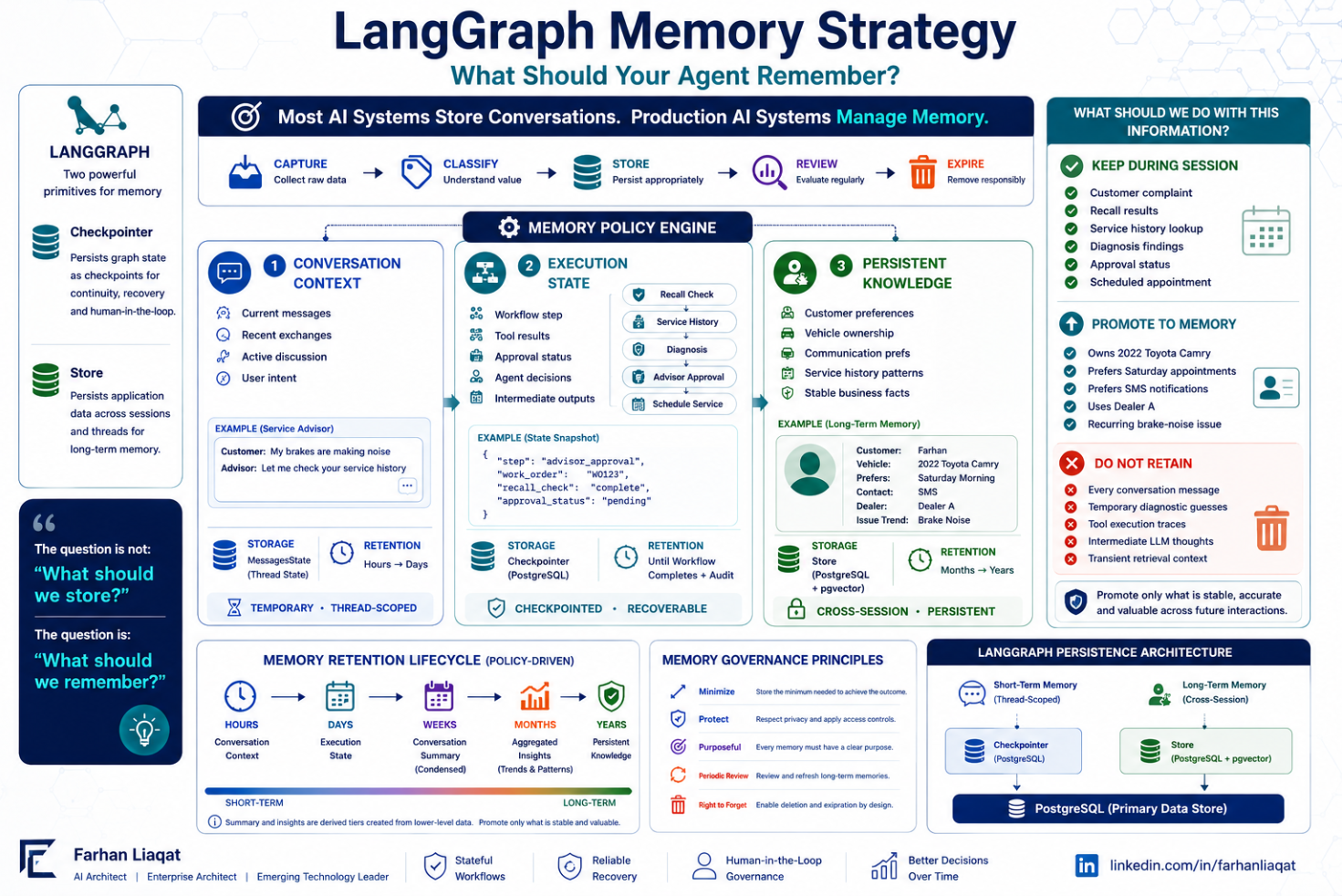
Conversation context, execution state, and persistent knowledge solve different problems and should not be stored the same way.
The first layer is conversation context. This is the live exchange. The current messages, the recent turns, the customer telling you the brakes are making noise and the advisor saying let me check your history. In LangGraph this lives in the graph state as something like a MessagesState, persisted through a checkpointer and scoped to a single thread. It matters while the conversation is happening. After the visit, most of it is disposable. You do not need the exact wording of every sentence six months from now.
The second layer is execution state. This is the workflow itself, not the chat around it. Which step are we on? What did the recall check return? What did the tools return? Is the advisor approval still pending?
This is the layer you checkpoint, and it is the layer that saves you. A LangGraph checkpointer writes a snapshot of graph state at every superstep, so when something interrupts the workflow, you resume from the last good checkpoint instead of starting over. If a node fails mid-run, the writes from the nodes that already finished are preserved, so resuming does not re-run work that was already done. This is also exactly what makes human-in-the-loop safe. The workflow can stop at the approval step, wait however long it needs to, survive a restart in the meantime, and pick up precisely where it left off when the advisor finally clicks approve.
The third layer is persistent knowledge. This is the small set of stable facts worth carrying across every future visit. That this customer owns a 2022 Camry. That they prefer Saturday mornings. That they want SMS, not email. That they keep coming back about brake noise.
In LangGraph this does not belong in the checkpointer at all, because the checkpointer is scoped to a single thread and a single conversation. It belongs in a store, where memories are organized under namespaces scoped to the customer rather than the session. A returning customer opening a brand new conversation still gets recognized, because the knowledge was never tied to the old thread in the first place.
Confusing those last two is the single most common production mistake I see.
Thread scope is for the current session. User scope is for the relationship. Putting durable customer facts in thread-scoped state means they vanish the moment the customer starts a new conversation, and you are back to an agent with amnesia.
The hard part is what moves between the layers
The architecture is not the difficult bit. The checkpointer and the store are a few lines of configuration. The difficult bit is the policy that decides what is worth promoting from one layer to the next, and what should never be kept at all.
A simple framework carries most of the weight.
Some things you keep only during the session. The specific complaint, the recall lookup results, the current diagnosis, the approval status, the live workflow context. These are essential right now and irrelevant next quarter. They live in thread state and they expire with the thread.
Some things you promote to long-term memory. The customer owns a 2022 Camry. They prefer Saturday appointments. They want SMS notifications. They have a recurring brake-noise issue worth watching. These are stable, they are valuable across future interactions, and they are what turn a generic agent into one that feels like it knows the customer.
And some things you should never retain at all. Every raw conversation message. Temporary diagnostic guesses the model floated and discarded. Tool execution traces. Intermediate model reasoning. Transient retrieval context. These exist to produce an answer in the moment, not to become a permanent record. Keeping them does not make the agent smarter. It makes it slower, more expensive, and harder to secure.
Memory needs a lifecycle, not a landfill
The cleanest way to hold all of this together is to treat memory as something with a lifecycle rather than a bucket that only ever fills up.
Capture what happens. Classify it into the right layer. Store it at the right scope. Review what made it into long-term memory, because facts go stale and a preference from two years ago may no longer hold. Expire what no longer earns its place.
LangGraph supports configurable time-to-live on memories, so expiry can be a deliberate policy rather than a cleanup script someone forgets to write. Nothing should become permanent simply because no one decided to remove it.
This is also where governance stops being a compliance afterthought and becomes part of the architecture.
Store the minimum you need to reach the outcome. Apply access controls and respect privacy. Give every stored memory a clear purpose. Review long-term memory on a schedule. Design for deletion from the start, because the right to forget is not optional in most enterprise contexts, and it is far easier to honor when forgetting was built in rather than bolted on.
What the customer actually feels
When the memory strategy is right, none of this is visible to the person in the service lane.
That is the point.
The workflow survives the restart and resumes exactly where it stopped. The half-finished approval is still waiting, not lost. The customer is not asked the same questions twice. The next time they come in, the agent already knows the car, the preferences, and the history of that nagging brake issue, so the conversation starts from context instead of from zero.
The work moves faster. The first-time fix rate goes up. Costs come down because you are not paying to reprocess everything on every turn. Sensitive data is not sitting in storage long after it stopped being useful.
Better context. Reliable workflows. Personalized experiences. Higher business value.
All of it traces back to one set of decisions about what to remember and what to let go.
The decision that actually matters
For years the conversation around enterprise AI has been about bigger models, larger context windows, and more powerful infrastructure. Memory has mostly been treated as a place to put things.
The more I work on production agentic systems, the more I think the important shift is smaller and harder.
It is not how much your agent can store.
It is how deliberately it decides what is worth keeping.
In many cases the most important architectural decision is not what your AI remembers.
It is what your AI intentionally forgets.
How are you handling memory governance in your agentic systems? Are you promoting facts to long-term memory on a fixed policy, or letting the model decide what is worth keeping?


